

Este é o primeiro duma serie de artigos que irei publicar, desvendando alguns ‘segredos’ do funcionamento desta espectacular plataforma de serviços que funcionam na Web. Dizemos que são ‘segredos’, porque a maior parte da informação que discutiremos convosco foi providenciada pela Google e está disponível a quem quiser. Óbvio que procuraremos usar uma linguagem mais simples possível, tecnicamente acessível a maior parte de nós. Estamos em crer que é bastante interessante o que temos para vos relatar. A razão porque escolhemos a Google foi por termos verificado que esta corporação que iniciou numa sala dum laboratório universitário em Stanford, tornou-se poderosa, a ponto de consagrar-se um provedor de telecomunicações, publicidade, entretenimento, computação e acima de tudo começa a assumir posições de padronizador/dinamizador em campos de pesquisa absolutamente emergentes hoje em dia, como o BIGData que iremos falar mais adiante.
Eu queria iniciar por contar-vos uma pequena historia: Em 2004/2005 enquanto técnico médio e programador Web freelancer em ASP/ASP.Net/C#/SQL Server fui assistir a conferencia na UCAN que consagrou a já defunta Associaçao Angolana de Software Livre (ASL).
A conferencia estava cheia de gente com bagagem de primeiro grau, como por exemplo Dr Pedro Teta, Eng Dimonekene Ditutala e Msc Mateus Padoca Calado. No entanto o que me chamou mesmo a atenção, foi a declaração do Dr Aires Veloso (um experiente docente de programação), onde ressaltou que um sistema a serio tinha de ser criado com uma framework/linguagem de verdade, tal como .Net ou Java.
Aquelas palavras ficaram-me na mente, ainda mais, porque não possuía conhecimentos sobre computação paralela. Somente anos depois, percebi que fazia todo sentido ele ter dito aquilo. Aquela era a época dominada por linguagens para desenvolvimento dinâmico como Cold Fusion Modules (CFM), ASP e um tal de PHP, lol. Estas eram, na altura, linguagens não orientadas a objectos e sem suporte a computação paralela.
Por isso era somente natural que um serviço de buscas e publicidade como o Google que crescia a todo vapor se sentisse ‘tentado’ a optar por plataformas como ASP.Net e Java. Mas, nem pensar!!! O génio de Sergey Brin e Lauwrence Page ‘permitiu-os’ seguir um outro caminho: Optaram por utilizar uma linguagem que até então era desconhecida para a Web: O Python (esta linguagem que tive oportunidade de aprender enquanto estagiário numa das instituições governamentais).
De facto, Sergey e Larry, não a escolherem por acaso. Esta linguagem tinha suporte a orientação de objectos, sendo fortemente tipada (tipos de dados interessantes, como listas e dicionários) e sobretudo, é software livre. Tiveram ‘apenas’ o desafio de portar para a Web, porque até então não havia conhecimento do uso desta linguagem na Web de forma massiva, senão em desktop e também aí, muito mais em aplicações para administração de sistemas *.NIX.
Este desafio foi vencido recorrendo ao uso de CGI (Common Gateway Interface) sobre o servidor HTTP Apache, ou seja, por meio dessa interface era possível a código não nativo ser executado pelo Apache. Alguns de vocês deverão lembrar que antes de 2000 e um pouco posterior a isso programava-se para a Web até com linguagem C e C++ (na minha opinião algo terrível) justamente porque a CGI do Apache permitia essa versatilidade. Era algo estranho e inúmeros problemas de segurança envolvendo sobreposição de memoria (Buffer Overflow) sobre HTTP foram revelados. Mas isto está fora do nosso contexto.
Esta decisão, longe de ser uma espécie de estilo NERD por parte de Sergey e Larry, foi antes uma estratégia de longo prazo que viria a influenciar toda a politica de crescimento da infra-estrutura da Google, ou seja, seria suportada por produtos de baixo preço, mas de elevado desempenho operacional, o que permitiria que sua infra-estrutura fosse facilmente escalável sobre custos baixos. Se a Google apostasse em desenvolver a sua infra-estrutura sobre frameworks como ASP.Net ou Java, corria o risco de ficar muito dependente de patentes e tecnologias de empresas que sabiam eles, mais cedo ou mais tarde, seriam seus adversários de negócios.
O problema do crescimento
Com o aumento da quantidade de informação produzida via Web, os serviços de indexação da google foram crescendo de tamanho. Por exemplo de 1999 a 2009, ou seja em 10 anos a google passou a indexar de 70 milhões a muitos biliões de documentos, a media da pedidos processados/dia aumentou cerca de 1000 vezes, cada documento passou a ter 3 (três) vezes mais informações nos serviços de indexação.
Gerir tamanha quantidade de informação (índices e documentos) mostrou desde o inicio ser um desafio e tanto para o pessoal da Google.
Como todo projecto vencedor tem uma base forte, a Google não foge a regra. E a sua força encontra-se também na excelente esquematizar da sua arquitectura, simples mas sobretudo inteligente.
A principio a Google adoptou a seguinte arquitectura (1997):
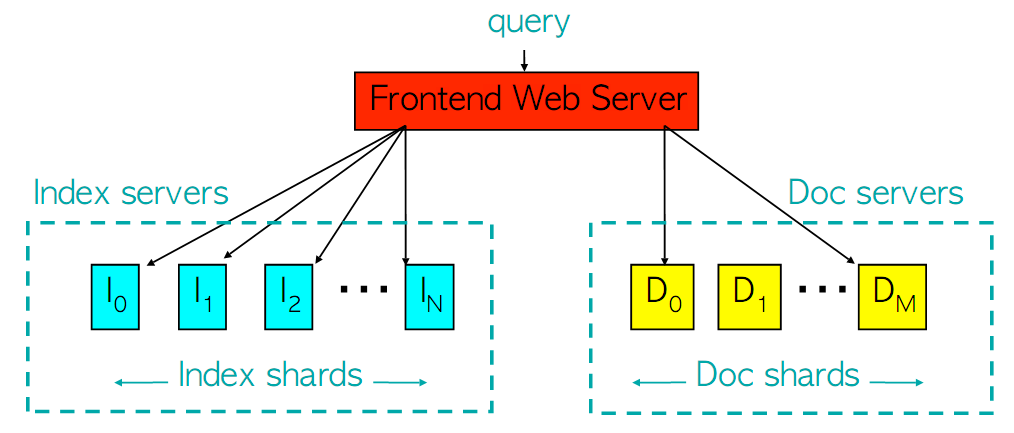
Apesar da sua aparente simplicidade, era uma arquitectura já aparentemente complexa possuindo elementos que estão a ser utilizados até hoje. Como podemos notar, existem dois grupos de servidores (clusters) que desempenham um papel importante por detrás dos pedidos de pesquisa (query) recebidos pelo servidor que chamaremos frontal (frontend): Os servidores de indexação e de documentação.
Os servidores de indexação possuem algumas informações sobre paginas, como por exemplo um índice invertido duma URL, do tipo ‘com.wordpress.snnangola‘. Os servidores de documentação armazenam todos os documentos possíveis existentes na Web e os ordenam aleatoriamente por fragmentos de documentação que falaremos mais abaixo. Cada documento possui propriedades tais como, um ID único conhecido como docid, um conjunto de palavras-chave que permitirão corresponde-lo a uma possível procura, e um Score atribuído pelo algoritmo PageRank.
Quando um pedido de pesquisa é enviado para servidor frontal, este encaminha para o servidor de indexação que mapeia individualmente cada palavra do pedido para uma lista de documentos relevantes. A relevância (Score) ou o grau de importância do documento, é determinada pelo PageRank. Essa relevância determina a ordem de saída dos documentos para a resposta ao pedido do usuário (melhor PageRank sai primeiro).
Essa aparente facilidade, entretanto esconde uma alta complexidade. Como já dissemos, com o aumento do numero de documentos, usuários e mobilidade na Web, o numero de pedidos de pesquisa/segundo aumentou brutalmente, o que perigosamente poderia aumentar o latência (o atraso ou RTT time) na resposta aos pedidos dos usuários, afinal haveria mais pedidos disputando entre si, sobre quem seria atendido primeiro. Felizmente a Google também tem uma solução para este problema, recorrendo a computação paralela. Como assim?
Pela figura acima observamos que tanto os servidores de indexação, como os servidores de documentos, possuem fragmentos (shards). Interessa de facto, falar sobre os fragmentos de indexação, porque estes lidam directamente com os pedidos dos usuários, via servidor frontal, logo os servidores de indexação, estariam em teoria mais sujeitos a estresse. Bom, isto já não é um problema porque os fragmentos possuem aleatoriamente índices para um subconjuntos de documentos do índice total. Esta técnica é conhecida como particionamento da indexação por documento.
Isto constitui inúmeras vantagens, na medida que por exemplo, cada fragmento pode processar cada pedido independentemente, também melhora o desempenho do tráfego da rede, e facilita a gestão da manutenção de informação por documento.
Mas também tem os seus contras, na medida que cada fragmento precisa processar cada pedido, e cada palavra da pesquisa necessita de ser procurada em cada N fragmentos.
Para minimizar estes efeitos, os pedidos feitos a um fragmento são distribuídos a uma pool de servidores. Cada fragmento também está distribuído numa pool de servidores no cluster de indexação.
O processo de pesquisa pode então ser resumido da seguinte forma:
- O usuário digita uma única/serie de palavra(s) (como por exemplo: ‘capital de angola‘);
- O servidor frontal recebe o pedido e envia para um dos fragmentos localizado numa das pools do cluster de indexação;
- O fragmento dado a(s) palavra(s) corresponde a uma lista ordenada de documentos composta por docid, score, etc;
- Um dos fragmentos numa das pools do cluster de documentação recebe a mensagem do fragmento de indexação e dado o docid e a(s) palavra(s), gera um conjunto de documentos, composto por titulo e trecho. Claro que com o docid já é mais fácil localizar o documento completo no disco.
No entanto, isso levanta uma outra questão: Se um dos servidores dos cluster‘s de indexação/documentação vai abaixo, por qualquer motivo, a pesquisa é abolida? A reposta encontra-se na estratégia de computação distribuída que a Google adoptou desde o inicio.
Estratégia de computação distribuída
A google sempre adoptou uma estratégia de computação distribuída. Isso mesmo pode ser percebido pela sua arquitectura já descrita na figura acima, mas que actualizaremos já, sobre uma outra perspectiva na figura abaixo:
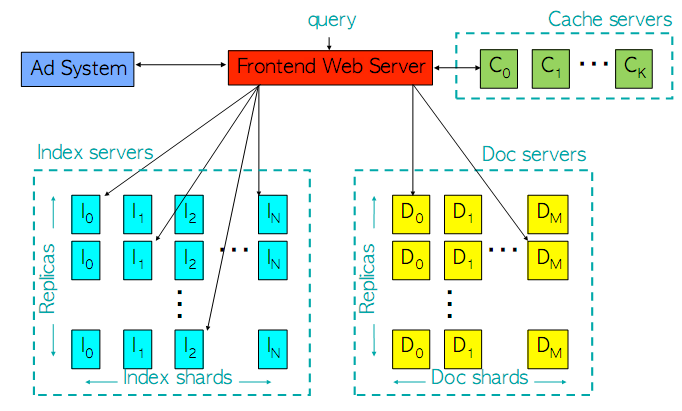
Podemos facilmente perceber as mudanças ocorridas:
- Introdução de replicação
- Introdução de caching
O investigador Português Jorge Cardoso no livro ‘Programação de sistemas distribuídos em JAVA, Editora FCA‘ escreveu que ‘o principio da localidade, admite que a comunicação entre computadores segue dois padrões distintos. Primeiro, é mais provável que um computador comunique com computadores que estejam mais próximos do que com computadores que estejam mais longe. Segundo, é provável que um computador comunique com o mesmo conjunto de computadores repetidamente‘.
Se você percebeu, notou claramente que o primeiro padrão é técnica de replicação, e o segundo a técnica de caching. Pela figura acima nota-se claramente a existência dos dois conceitos. Exactamente ao lado do servidor frontal notamos a presença dum conjunto de servidores de caching que não sabemos com toda certeza se pertencem a um cluster. Entretanto, isso é bastante útil, quando os usuários realizam pesquisas que não foram actualizadas. Nesse caso, se elas não mudaram então não é necessário encaminhar a pesquisa para o cluster de indexação, mas sim para o suposto cluster de caching que encaminha os documentos, já anteriormente pesquisados, para o usuário.
Pela figura acima notamos também a existência de replicação vertical nos fragmentos de indexação de de documentação. Isso é muito importante, na medida em que explica porque raramente sentimos uma pesquisa no Google ser abolida ou gerar um erro. Notamos, que ainda que um fragmento vá abaixo por causa dum erro lógico ou físico num dos servidores do cluster, pela capacidade de replicação, automaticamente a tarefa passa para outro fragmento pertencente a outra pool de servidores. Isso é uma maravilha, já que estamos em crer ser difícil que uma pool inteira falhe, mas mesmo que falhe haverá sempre outra pool para a substituir.
Por esta altura já conseguimos perceber porque o Google consegue responder de forma tão rápida as nossas pesquisas. Sim, existem outras técnicas e alguma delas iremos abordar mais adiante, no entanto, isso é em parte porque eles conseguem manter imagens de toda a Web replicadas em seus cluster’s de documentação por todo mundo.
Não existirão teoricamente muitos problemas de paginas armazenadas no cluster mas que já não existem nos servidores onde estavam alojadas. O sistema Google é inteligente o suficiente para verificar isso, e actualizar se possível, da forma mais rápida. Mas isso as vezes não acontecia tão rapidamente, e por um motivo muito simples. Os cluster’s da Google começaram a expandir-se muito rapidamente, até a escala global.
As vezes fazemos uma pesquisa a partir de Angola, e os resultados Web vem da Irlanda, mas os de Video (Youtube) vem do Brasil, o AdSense do Polo Norte (exagerei!!!) no entanto, não existe praticamente latência. Como tudo isso é possível? Se um cluster de documentação nos EUA actualiza os seus documentos, os cluster’s em todo mundo necessitam fazer isso de forma automática com mínimo de atrasos possíveis, sob pena de elevadas receitas serem perdidas.
O próximo artigo falará sobre isso.





